

SMART-LAB
Новый дизайн
Мы делаем деньги на бирже














Информация


 Новости тг-канал
Новости тг-каналData Mining
OHLCV: продолжение
- 14 января 2014, 15:26
- |

В прошлом посте я заявил что если вы торгуете OHLCV то я скорее всего знаю как вы зарабатываете.
Ну и чтобы не быть голословным, давно еще удалось отмайнить закономерность, существенно отличающую фРТС 2011-2013 от фРТС 2008-2010 годов.
Буквально на прошлой неделе ее и еще одну систему уже продает известный системостроитель за 300тысяч рублей.
Вот мой вариант системы:

К слову это не первая моя система которая так пересекается. Когда набор данных ограничен, все приходят к единой модели.
Ну и чтобы не быть голословным, давно еще удалось отмайнить закономерность, существенно отличающую фРТС 2011-2013 от фРТС 2008-2010 годов.
Буквально на прошлой неделе ее и еще одну систему уже продает известный системостроитель за 300тысяч рублей.
Вот мой вариант системы:

К слову это не первая моя система которая так пересекается. Когда набор данных ограничен, все приходят к единой модели.
- комментировать
- 323 | ★1
- Комментарии ( 5 )
Data Mining fRTS: тренд и флет ч.1
- 09 января 2014, 14:14
- |
Сегодня я хотел бы поговорить о внутренних параметрах fRTS, а именно о его склонности к трендовым и флетовым дням.

Скачать минутки frts: https://drive.google.com/file/d/0B9zer9va_1aoQkR2SEktLWx0QU0/edit?usp=sharing
Скачать исходный код: https://drive.google.com/file/d/0B9zer9va_1aoWkFUV191S3BBUFk/edit?usp=sharing
Итак на текущий момент мы выяснили что 20% самых трендовых дней на фРТС закрываются с рейнджем от 3164п.
Продолжение следует.
p.s. спасибо
( Читать дальше )

Скачать минутки frts: https://drive.google.com/file/d/0B9zer9va_1aoQkR2SEktLWx0QU0/edit?usp=sharing
Скачать исходный код: https://drive.google.com/file/d/0B9zer9va_1aoWkFUV191S3BBUFk/edit?usp=sharing
Итак на текущий момент мы выяснили что 20% самых трендовых дней на фРТС закрываются с рейнджем от 3164п.
Продолжение следует.
p.s. спасибо
( Читать дальше )
Data Mining fRTS: препарируем объемы
- 05 января 2014, 23:38
- |
В прошлом посте я писал о том, что для поиска торговых идеи часто бывает полезным задаваться вопросами. Сегодня я решил продолжить этот пост и провести более интересное исследование. Задача исследования, статистическим путем выяснить в какие часы дня проходят наибольшие объемы для фьючерса на индекс РТС (далее фРТС).
Для этого мы опять будем использовать язык R.

код: http://pastebin.com/38FNtub6
Полученная табличка:
( Читать дальше )
Для этого мы опять будем использовать язык R.
код: http://pastebin.com/38FNtub6
Полученная табличка:
( Читать дальше )
Сытый конному не леший: фокусы data mining
- 28 февраля 2013, 04:02
- |
Знаете, какой набор переменных лучше всего предсказывает S&P500? Ни за что не догадаетесь: это производство сливочного масла в Бангладеш и США + выпуск сыра в США + поголовье овец в США и Бангладеш. И это не совсем шутка — именно такой результат получили исследователи, когда попытались найти, какие переменные лучше всего скоррелированы с рынком акций.

На самом деле, конечно, это экстремальный пример так называемого overfitting — переподгонки. Будьте осторожны с корреляциями! ) И с моделями, основанными на истории — тоже. Модель, идеально описывающая исторические данные, может абсолютно идиотически вести себя в будущем. Яркий пример:
( Читать дальше )

На самом деле, конечно, это экстремальный пример так называемого overfitting — переподгонки. Будьте осторожны с корреляциями! ) И с моделями, основанными на истории — тоже. Модель, идеально описывающая исторические данные, может абсолютно идиотически вести себя в будущем. Яркий пример:
( Читать дальше )
Датамайнинг: кластеризация - вебинару быть
- 26 ноября 2012, 13:03
- |
Пока что небольшие техпроблемы, как только все решится, ссылка появится.
Методы Машинного обучения (Data Mining)
- 04 февраля 2012, 12:58
- |
Доказав себе однажды, что ни один из индикаторов по отдельности или в совокупности с другими работают неудовлетворительно (по тестам от 3-х лет и более) я пришел к простейшим методам Data Mining, которые показали очень хорошие результаты. Пришла пора капнуть глубже, тут как раз и аккуратненькая подборочка, для поверхностного ознакомления, нашлась.
А вы используете в своей торговле подобные штуки?
Метод опорных векторов
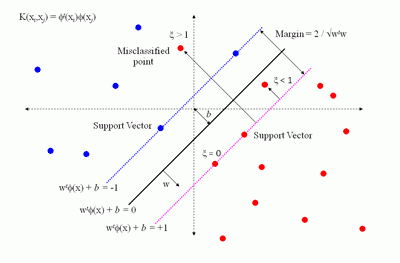
Метод опорных векторов был разработан Владимиром Вапником в 1995 году [86] и впервые применен к задаче классификации текстов Йоахимсом (Joachims) в 1998 году в работе. В своем первоначальном виде алгоритм решал задачу различения объектов двух классов. Метод приобрел огромную популярность благодаря своей высокой эффективности. Многие исследователи использовали его в своих работах, посвященных классификации текстов. Подход, предложенный Вапником для определения того, к какому из двух заранее определенных классов должен принадлежать анализируемый образец, основан на принципе структурной минимизации риска. Вероятность ошибки при классификации оценивается, как непрерывная убывающая функция, от расстояния между вектором и разделяющей плоскостью. Она равна 0,5 в нуле и стремится к 0 на бесконечности.
( Читать дальше )
А вы используете в своей торговле подобные штуки?
Метод опорных векторов
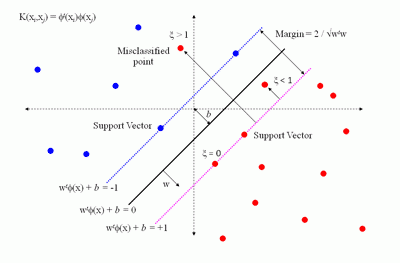
Метод опорных векторов был разработан Владимиром Вапником в 1995 году [86] и впервые применен к задаче классификации текстов Йоахимсом (Joachims) в 1998 году в работе. В своем первоначальном виде алгоритм решал задачу различения объектов двух классов. Метод приобрел огромную популярность благодаря своей высокой эффективности. Многие исследователи использовали его в своих работах, посвященных классификации текстов. Подход, предложенный Вапником для определения того, к какому из двух заранее определенных классов должен принадлежать анализируемый образец, основан на принципе структурной минимизации риска. Вероятность ошибки при классификации оценивается, как непрерывная убывающая функция, от расстояния между вектором и разделяющей плоскостью. Она равна 0,5 в нуле и стремится к 0 на бесконечности.
( Читать дальше )
Применение data mining в оптимизации ТС.
- 07 марта 2011, 00:38
- |
Как можно улучшить результаты системы, используя методы data mining? Самое элементарное — это использовать кластерный анализ на некоторых данных. Допустим, у вас есть функция f(x,y,...). Можно исследовать поведение этой функции на разных кластерах значений аргументов. Иногда, можно выделить несколько кластеров значений аргументов, на которых функция ведет себя с некоторой закономерностью. И далее уже анализируя эту закономерность — написать правило. Главное, не перегнуть палку с такого рода оптимизацией. Является ли это подстройкой под кривую? Я думаю, это зависит от функции f. Что она из себя представляет? Есть некоторые фундаментальные законы поведения рынов, которые заставляют самые обычные индикаторы вести себя определенным образом. Эти вещи можно попытаться использовать. Тестирование нужно проводить на самых разных рынках: волатильные, трендовые, стремительно падающие, спокойные. Если правило улучшает все рынки — правило годное. К сожалению мне не хватает знаний в этой области, а идеи как это применить — есть. Придется видимо почитать что-нибудь по теме.
( Читать дальше )
( Читать дальше )
- bitcoin
- brent
- cnyrub
- eurusd
- forex
- gbpusd
- imoex
- ipo
- nyse
- s&p500
- si
- usdrub
- акции
- алготрейдинг
- алроса
- анализ
- аналитика
- аэрофлот
- банки
- биржа
- биткоин
- брокеры
- валюта
- вдо
- волновая разметка
- волновой анализ
- вопрос
- втб
- газ
- газпром
- гмк норникель
- дивиденды
- доллар
- доллар рубль
- дональд трамп
- евро
- золото
- инвестиции
- инвестиции в недвижимость
- индекс мб
- инфляция
- инфляция в россии
- китай
- ключевая ставка цб рф
- кризис
- криптовалюта
- лукойл
- магнит
- мобильный пост
- мосбиржа
- московская биржа
- мтс
- натуральный газ
- нефть
- новатэк
- новости
- обзор рынка
- облигации
- опрос
- опционы
- отчеты мсфо
- офз
- оффтоп
- портфель инвестора
- прогноз
- прогноз по акциям
- путин
- раскрытие информации
- роснефть
- россия
- ртс
- рубль
- рынки
- рынок
- санкции
- сбер
- сбербанк
- сво
- северсталь
- смартлаб
- сущфакты
- сша
- технический анализ
- торговля
- торговые роботы
- торговые сигналы
- трейдинг
- украина
- финансы
- фондовый рынок
- форекс
- фрс сша
- фьючерс mix
- фьючерс ртс
- фьючерсы
- цб рф
- экономика
- экономика россии
- юмор
- яндекс