

SMART-LAB
Новый дизайн
Мы делаем деньги на бирже














Информация


 Новости тг-канал
Новости тг-каналИзбранное трейдера MrD
Неэффективные рынки. Теория Доу.
- 26 января 2012, 16:59
- |

Если немного «перепеть» классика, то тренд характеризуется, тем что каждый лоу выше/ниже предыдущего при аптренде/доунтренде. Попытаемся проверить насколько эти представления актуальны. Для этого возьмем дневки Ри, за 2010-2011 год и посчитаем разницу между лоу текущего дня и предыдущего, то есть LowDelta = Low[Day] — Low[Day — 1]. Нас будет интересовать насколько значения этого ряда, автоскоррелированы, то есть при аптренде если верить теории Доу, положительные значения LowDelta должны следовать за положительными, а отрицательные за отрицательными. Соответственно получим числовой ряд этих LowDelta выглядящий следующим образом:

На первый взгляд — просто шум, но мы немного углубимся в его анализ. ) Нас будет интересовать насколько значения этого ряда, автоскоррелированы, то есть при аптренде если верить теории Доу, положительные значения LowDelta должны следовать за положительными, а отрицательные за отрицательными. Чтобы как-то выразить эти соотношения математически, введем второй фактор — значение LowDelta, за предыдущий день обозначим его LagLowDelta = Lag(LowDelta, 1) = Low[Day — 1] — Low[Day — 2]. Теперь нарисуем, пары значений (LowDelta по X, LagLowDelta по Y):
( Читать дальше )
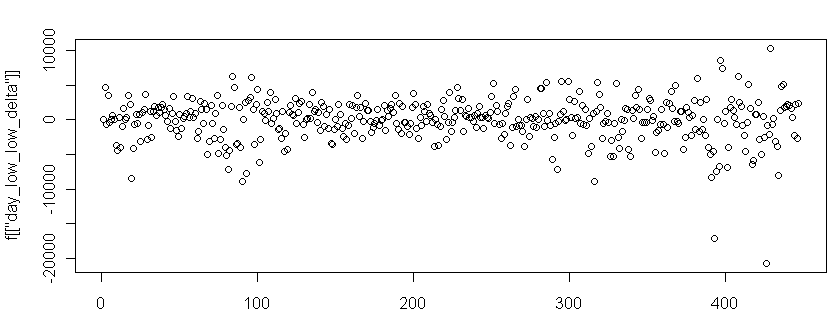
На первый взгляд — просто шум, но мы немного углубимся в его анализ. ) Нас будет интересовать насколько значения этого ряда, автоскоррелированы, то есть при аптренде если верить теории Доу, положительные значения LowDelta должны следовать за положительными, а отрицательные за отрицательными. Чтобы как-то выразить эти соотношения математически, введем второй фактор — значение LowDelta, за предыдущий день обозначим его LagLowDelta = Lag(LowDelta, 1) = Low[Day — 1] — Low[Day — 2]. Теперь нарисуем, пары значений (LowDelta по X, LagLowDelta по Y):
( Читать дальше )
- комментировать
- ★9
- Комментарии ( 13 )
Hunting high and low (updated)
- 22 октября 2011, 14:09
- |
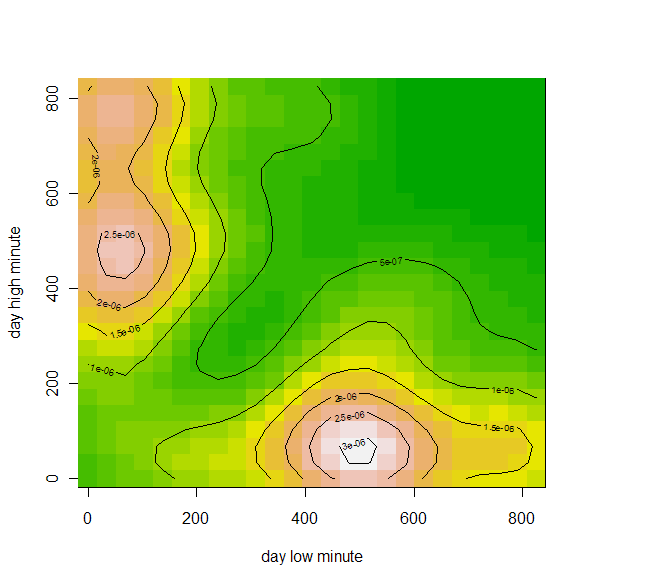
Данные фьючерс РТС за 10-11 год(всего 477 точек), время в минутах(начиная с 10:00) дневного хая и лоя.
(взаимная плотность, по x — время лоя, по y — время хая)
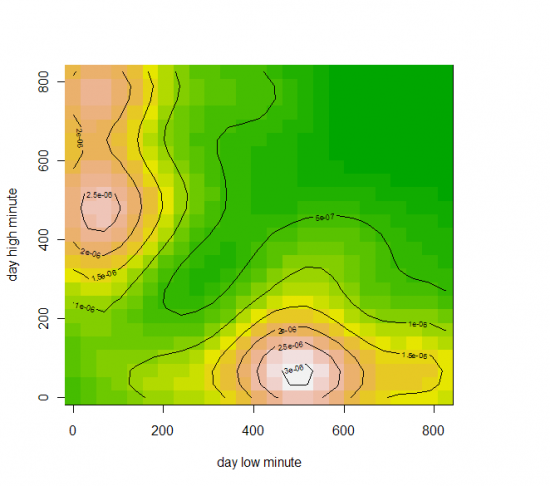
Собственно, что мы видим, есть два типа дней, у одних наиболее вероятный хай в районе 11 часов, а лой в 500 минут от 10:00 (то есть 18:20), второй наиболее вероятный лой в районе 11 часов, а хай в ~470 минут от 10:00 (то есть 17:50-18:00). Соответственно, попытки войти со среднесрочным горизонтом и коротким стопом в другие промежутки времени, резко увеличивает вероятсноть, что вы поймаете стоп.
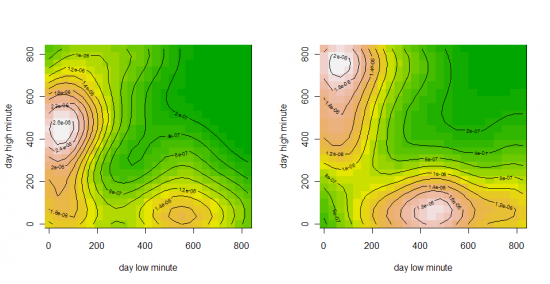
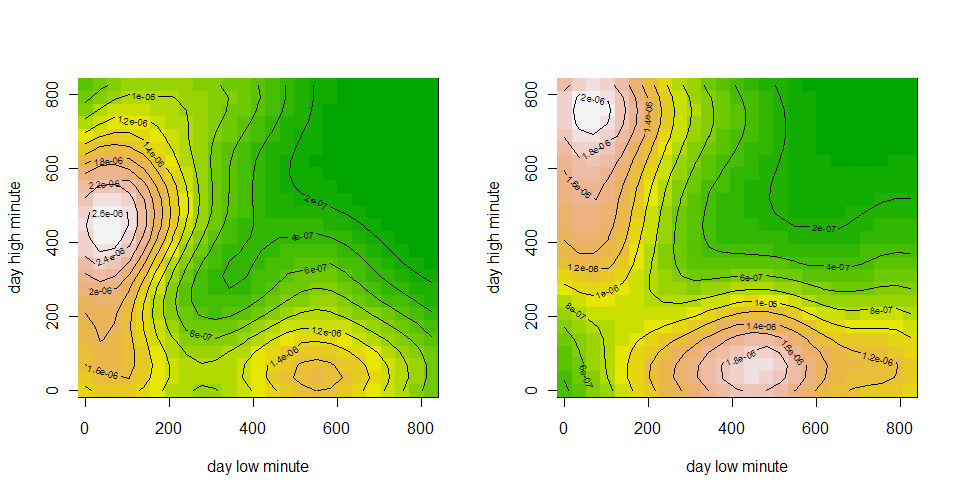
UPDATE: то же самое но с разбивкой по дням недели.
Понедельник, Вторник
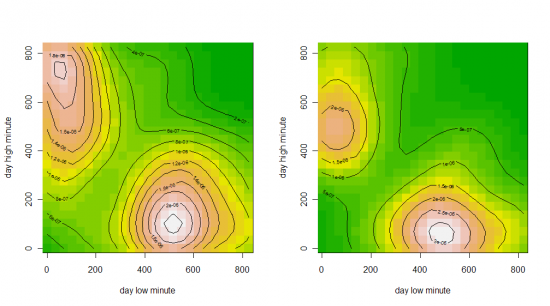
Среда, Четверг
Пятница

(взаимная плотность, по x — время лоя, по y — время хая)
Собственно, что мы видим, есть два типа дней, у одних наиболее вероятный хай в районе 11 часов, а лой в 500 минут от 10:00 (то есть 18:20), второй наиболее вероятный лой в районе 11 часов, а хай в ~470 минут от 10:00 (то есть 17:50-18:00). Соответственно, попытки войти со среднесрочным горизонтом и коротким стопом в другие промежутки времени, резко увеличивает вероятсноть, что вы поймаете стоп.
UPDATE: то же самое но с разбивкой по дням недели.
Понедельник, Вторник
Среда, Четверг
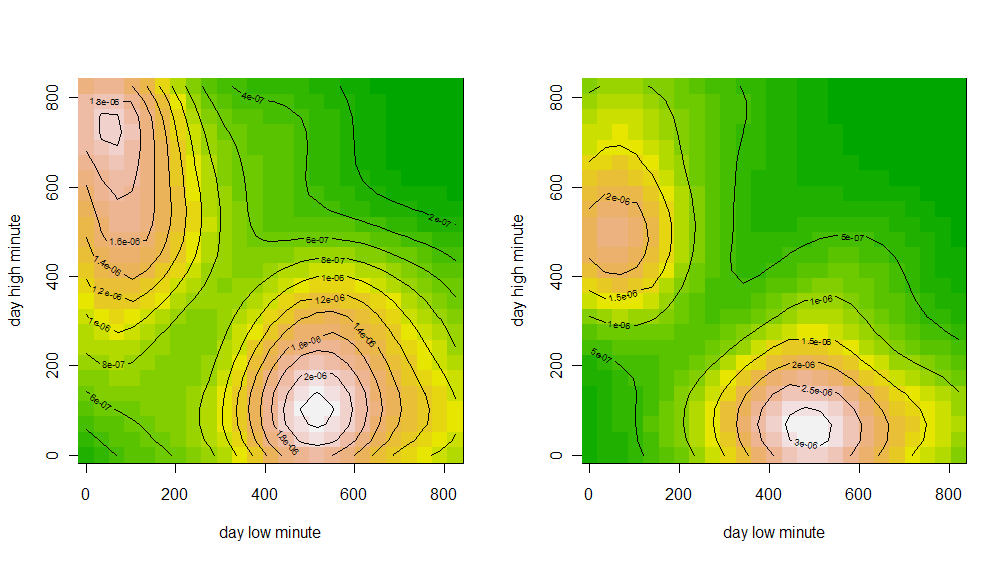
Пятница

Исследование индекса оптимизма Smart Lab. Часть 2
- 25 сентября 2011, 20:34
- |
В предыдущей серии, мы пересчитали значении индекса, а так же нашли его корреляцию с приращениями индекса RTS, таким образом построив простейшую модель (Корреляция: 38.8%, СКО ошибки: 0.235), на этот раз мы попробуем значительно ее улучшить.
Для каждого из используемых факторов: Индекс РТС, индекс ММВБ, акции Сбербанк, акции Газпром, индекс Bovespa, индекс S&P, фьючер на нефть марки BRENT, фьючерс на золото и фьючерс на пару рубль/доллар, посчитаем: приращения логарифма (logdelta = log(Close) — log(Open)). По которым построим линейную регрессию этих приращений и значений индекса оптимизма. То есть формулу вида: индекс оптимизма = A0 + A1*РТС logdelta + A2*ММВБ logdelta + A3*S&P logdelta +…. В результате получим, что два статистически значимых фактора, приращения индекса РТС и индекса ММВБ, и здесь нас ждет первая неожиданность: значимыми оказываются не сами приращения, а их разница (то есть, приращение индекса РТС — приращение индекса ММВБ).
Таким образом выделим новый фактор: РТС logdelta — ММВБ logdelta, и попробуем построить на его основе модель (аналогичную той что была в первой части). Получим:
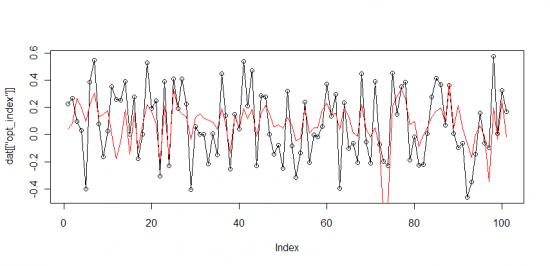
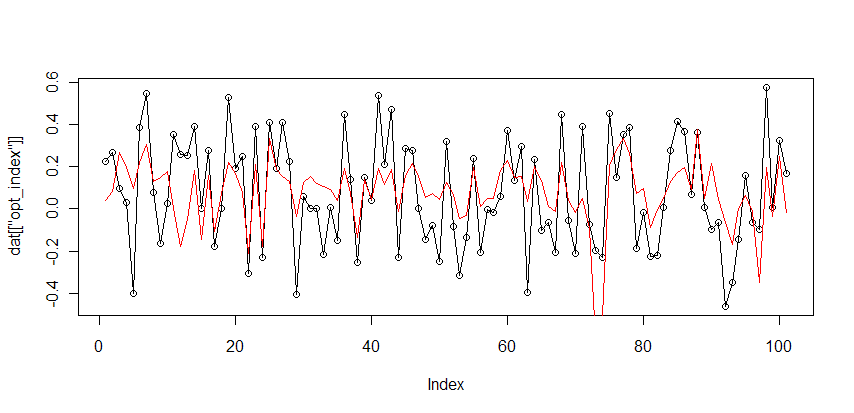
индекс оптимизма = 15.77*(РТС logdelta — ММВБ logdelta) + 0.095
(черным значения индекса, красным предсказания модели)
( Читать дальше )
Для каждого из используемых факторов: Индекс РТС, индекс ММВБ, акции Сбербанк, акции Газпром, индекс Bovespa, индекс S&P, фьючер на нефть марки BRENT, фьючерс на золото и фьючерс на пару рубль/доллар, посчитаем: приращения логарифма (logdelta = log(Close) — log(Open)). По которым построим линейную регрессию этих приращений и значений индекса оптимизма. То есть формулу вида: индекс оптимизма = A0 + A1*РТС logdelta + A2*ММВБ logdelta + A3*S&P logdelta +…. В результате получим, что два статистически значимых фактора, приращения индекса РТС и индекса ММВБ, и здесь нас ждет первая неожиданность: значимыми оказываются не сами приращения, а их разница (то есть, приращение индекса РТС — приращение индекса ММВБ).
Таким образом выделим новый фактор: РТС logdelta — ММВБ logdelta, и попробуем построить на его основе модель (аналогичную той что была в первой части). Получим:
индекс оптимизма = 15.77*(РТС logdelta — ММВБ logdelta) + 0.095
(черным значения индекса, красным предсказания модели)
( Читать дальше )
Исследование индекса оптимизма Smart Lab. Часть 1
- 18 сентября 2011, 18:18
- |
Насколько предсказуемо поведение индекса оптимизма? Какие внешние факторы на него влияют, а на сколько это «вещь в себе»? Попытаемся ответить на эти вопросы в ходе исследования.
Прежде всего, обратимся к тому как он собственно расчитывается, на данный момент используется довольно простая формула Количество Быков/Количество Медведей. При этом возникают следующие проблемы: распределение индекса совсем не симметрично, резкое изменение соотношения приводит к серьезным «выбросам» (тяжелые хвосты распределения).
<cut>
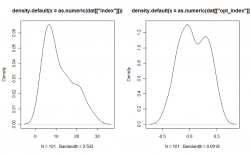
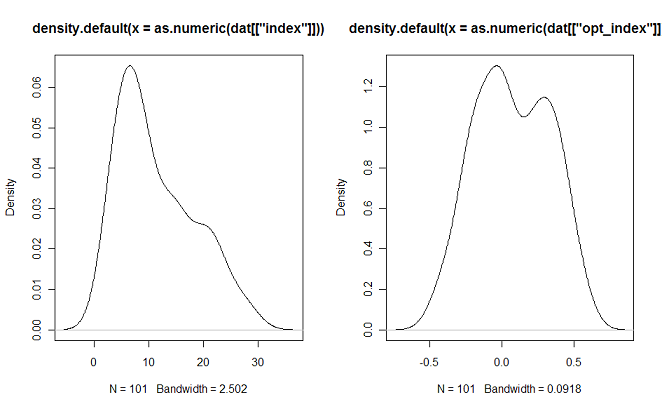
Поэтому первым делом приведем его к более приемлемому со статистической точки зрения виду. Для этого пересчитаем индекс следующим образом: Процент Быков — Процент Медведей или (X — Y)/(X+Y). Сравним распределение индекса построенного по оригинальной(cлева) и предложенной формуле(справа):
( Читать дальше )
Прежде всего, обратимся к тому как он собственно расчитывается, на данный момент используется довольно простая формула Количество Быков/Количество Медведей. При этом возникают следующие проблемы: распределение индекса совсем не симметрично, резкое изменение соотношения приводит к серьезным «выбросам» (тяжелые хвосты распределения).
<cut>
Поэтому первым делом приведем его к более приемлемому со статистической точки зрения виду. Для этого пересчитаем индекс следующим образом: Процент Быков — Процент Медведей или (X — Y)/(X+Y). Сравним распределение индекса построенного по оригинальной(cлева) и предложенной формуле(справа):
( Читать дальше )
- bitcoin
- brent
- eurusd
- forex
- gbpusd
- gold
- imoex
- ipo
- nasdaq
- nyse
- rts
- s&p500
- si
- usdrub
- wti
- акции
- алготрейдинг
- анализ
- аналитика
- аэрофлот
- банки
- биржа
- биткоин
- брокеры
- валюта
- вдо
- волновой анализ
- волны эллиотта
- вопрос
- втб
- газ
- газпром
- гмк норникель
- дивиденды
- доллар
- доллар рубль
- евро
- золото
- инвестиции
- инфляция
- китай
- коронавирус
- кризис
- криптовалюта
- лидеры роста и падения ммвб
- лукойл
- магнит
- ммвб
- мобильный пост
- мосбиржа
- московская биржа
- нефть
- новатэк
- новости
- обзор рынка
- облигации
- опек+
- опрос
- опционы
- офз
- оффтоп
- прогноз
- прогноз по акциям
- путин
- раскрытие информации
- ри
- роснефть
- россия
- ртс
- рубль
- рынки
- рынок
- санкции
- сбер
- сбербанк
- северсталь
- си
- сигналы
- смартлаб
- сущфакты
- сша
- технический анализ
- торговля
- торговые роботы
- торговые сигналы
- трейдер
- трейдинг
- украина
- финансы
- фондовый рынок
- форекс
- фрс
- фьючерс
- фьючерс mix
- фьючерс ртс
- фьючерсы
- цб
- экономика
- юмор
- яндекс