

SMART-LAB
Новый дизайн
Мы делаем деньги на бирже














Информация


vlad1024




ЛЧИ, данные 2
- 07 января 2012, 16:56
- |

В продолжение http://smart-lab.ru/blog/19153.php.
Архив всех данных cо скриптами, и стратегией для WealthLab 5 которая их визуализирует, за лчи2011: http://narod.ru/disk/36794566001/lchi.rar.html
В корни архива, lchi/VisualizeStrategy.wld стратегия для WealtLab 5 которая визуализирует агрегированные данные (что это такое расписанно в предыдущем посте по верхней ссылке). Для этого:
1. экспортируйте данные по инструменту в data sets за период лчи. (например через Ascii Files, данные от финама в папке lchi/rts_m1_lchi)
2. создать новую пустую стратегию File->New->New Strategy From Code
в открывшуюся новую стратегию, скопировать и заменить код из VisualizeStrategy.wld
3. единственный параметр стратегии это filePath, идет первой строкой в методе Execute. В него необходимо прописать полный путь до файла содержащего агрегированные с лчи данные по инструменту.
Например если распаковать, архив lchi.rar в катало c:/project и мы хотим посмотреть торговлю dr-mart на ri:
( Читать дальше )
Архив всех данных cо скриптами, и стратегией для WealthLab 5 которая их визуализирует, за лчи2011: http://narod.ru/disk/36794566001/lchi.rar.html
В корни архива, lchi/VisualizeStrategy.wld стратегия для WealtLab 5 которая визуализирует агрегированные данные (что это такое расписанно в предыдущем посте по верхней ссылке). Для этого:
1. экспортируйте данные по инструменту в data sets за период лчи. (например через Ascii Files, данные от финама в папке lchi/rts_m1_lchi)
2. создать новую пустую стратегию File->New->New Strategy From Code
в открывшуюся новую стратегию, скопировать и заменить код из VisualizeStrategy.wld
3. единственный параметр стратегии это filePath, идет первой строкой в методе Execute. В него необходимо прописать полный путь до файла содержащего агрегированные с лчи данные по инструменту.
Например если распаковать, архив lchi.rar в катало c:/project и мы хотим посмотреть торговлю dr-mart на ri:
( Читать дальше )
- комментировать
- 135 | ★38
- Комментарии ( 7 )
Hunting high and low (updated)
- 22 октября 2011, 14:09
- |
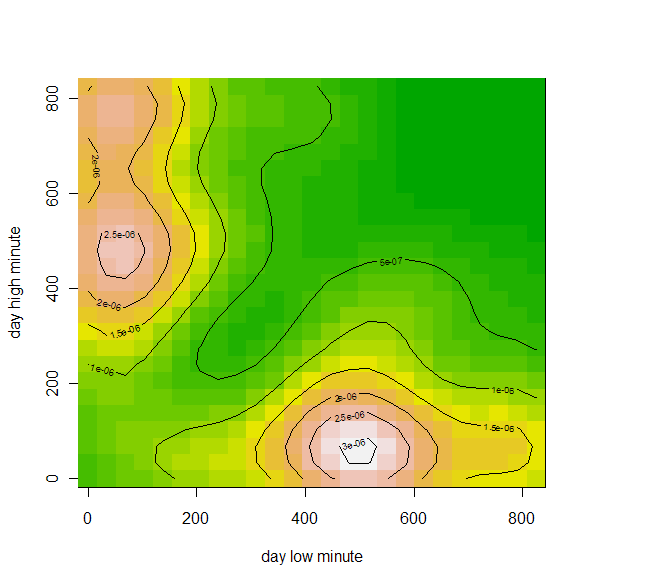
Данные фьючерс РТС за 10-11 год(всего 477 точек), время в минутах(начиная с 10:00) дневного хая и лоя.
(взаимная плотность, по x — время лоя, по y — время хая)
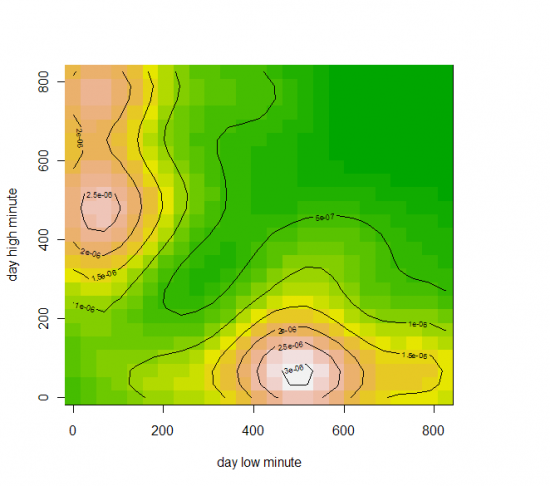
Собственно, что мы видим, есть два типа дней, у одних наиболее вероятный хай в районе 11 часов, а лой в 500 минут от 10:00 (то есть 18:20), второй наиболее вероятный лой в районе 11 часов, а хай в ~470 минут от 10:00 (то есть 17:50-18:00). Соответственно, попытки войти со среднесрочным горизонтом и коротким стопом в другие промежутки времени, резко увеличивает вероятсноть, что вы поймаете стоп.
UPDATE: то же самое но с разбивкой по дням недели.
Понедельник, Вторник
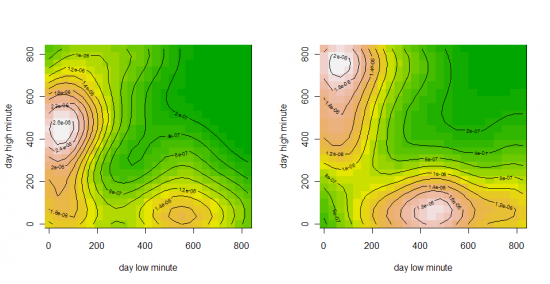
Среда, Четверг
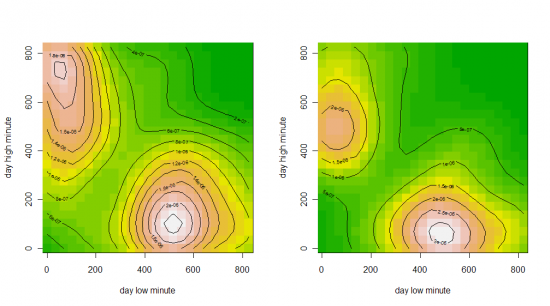
Пятница

(взаимная плотность, по x — время лоя, по y — время хая)
Собственно, что мы видим, есть два типа дней, у одних наиболее вероятный хай в районе 11 часов, а лой в 500 минут от 10:00 (то есть 18:20), второй наиболее вероятный лой в районе 11 часов, а хай в ~470 минут от 10:00 (то есть 17:50-18:00). Соответственно, попытки войти со среднесрочным горизонтом и коротким стопом в другие промежутки времени, резко увеличивает вероятсноть, что вы поймаете стоп.
UPDATE: то же самое но с разбивкой по дням недели.
Понедельник, Вторник
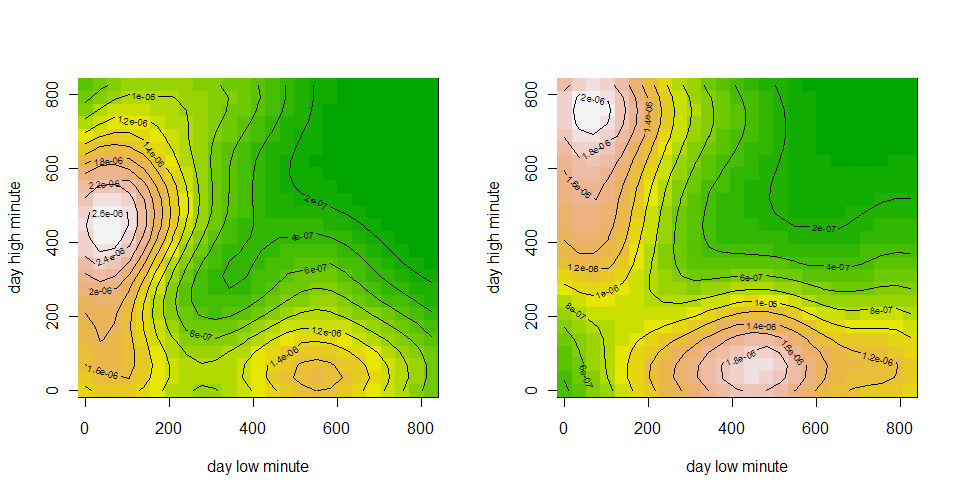
Среда, Четверг
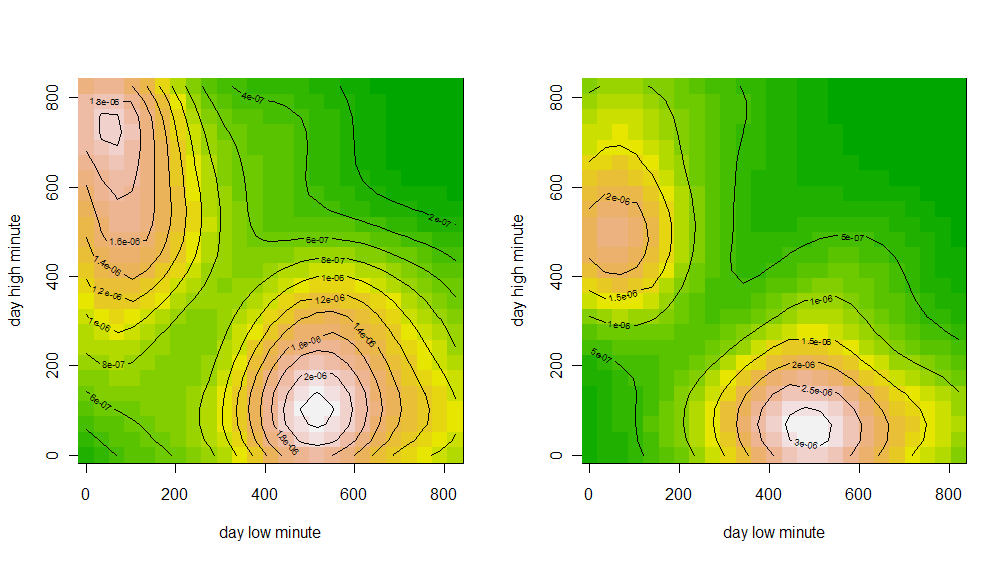
Пятница

ЛЧИ, данные
- 09 октября 2011, 12:51
- |
Скрипты на питоне для выкачивания данных из статистики ЛЧИ и пост процессинга:
http://narod.ru/disk/27799043001/lchi_script3.rar.html
Как использовать?
1. Скачать и установить сборку питона(если не установлен)
http://sourceforge.net/projects/numpy/files/NumPy/1.4.1/numpy-1.4.1-win32-superpack-python2.6.exe/download
.
http://www.python.org/ftp/python/2.6.2/python-2.6.2.msi
2. Набрать в командной строке «python» должна появится консоль питона (если нет, прописать в PATH путь к интерпретатору)
3. Скрипт download.py скачивает данные для заданного года и участника. Например: python download.py 2011 dr-mart
4. Скрипт agregate.py агрегирует скаченные данные (раскладывает по инструментам, фиксит вечернюю сессию в хронологический порядок, немного склеивает сделки, и считает балансовую позицию)
Например: python agregate.py 2011 dr-mart
5. В результате должно получится(dr-mart_RIZ1.csv):
code,direction,price,amount,time,date,balance
( Читать дальше )
http://narod.ru/disk/27799043001/lchi_script3.rar.html
Как использовать?
1. Скачать и установить сборку питона(если не установлен)
http://sourceforge.net/projects/numpy/files/NumPy/1.4.1/numpy-1.4.1-win32-superpack-python2.6.exe/download
.
http://www.python.org/ftp/python/2.6.2/python-2.6.2.msi
2. Набрать в командной строке «python» должна появится консоль питона (если нет, прописать в PATH путь к интерпретатору)
3. Скрипт download.py скачивает данные для заданного года и участника. Например: python download.py 2011 dr-mart
4. Скрипт agregate.py агрегирует скаченные данные (раскладывает по инструментам, фиксит вечернюю сессию в хронологический порядок, немного склеивает сделки, и считает балансовую позицию)
Например: python agregate.py 2011 dr-mart
5. В результате должно получится(dr-mart_RIZ1.csv):
code,direction,price,amount,time,date,balance
( Читать дальше )
Исследование индекса оптимизма Smart Lab. Часть 2
- 25 сентября 2011, 20:34
- |
В предыдущей серии, мы пересчитали значении индекса, а так же нашли его корреляцию с приращениями индекса RTS, таким образом построив простейшую модель (Корреляция: 38.8%, СКО ошибки: 0.235), на этот раз мы попробуем значительно ее улучшить.
Для каждого из используемых факторов: Индекс РТС, индекс ММВБ, акции Сбербанк, акции Газпром, индекс Bovespa, индекс S&P, фьючер на нефть марки BRENT, фьючерс на золото и фьючерс на пару рубль/доллар, посчитаем: приращения логарифма (logdelta = log(Close) — log(Open)). По которым построим линейную регрессию этих приращений и значений индекса оптимизма. То есть формулу вида: индекс оптимизма = A0 + A1*РТС logdelta + A2*ММВБ logdelta + A3*S&P logdelta +…. В результате получим, что два статистически значимых фактора, приращения индекса РТС и индекса ММВБ, и здесь нас ждет первая неожиданность: значимыми оказываются не сами приращения, а их разница (то есть, приращение индекса РТС — приращение индекса ММВБ).
Таким образом выделим новый фактор: РТС logdelta — ММВБ logdelta, и попробуем построить на его основе модель (аналогичную той что была в первой части). Получим:
индекс оптимизма = 15.77*(РТС logdelta — ММВБ logdelta) + 0.095
(черным значения индекса, красным предсказания модели)
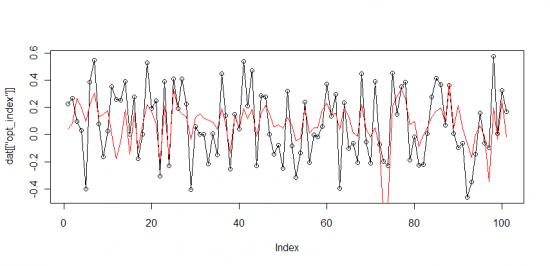
( Читать дальше )
Для каждого из используемых факторов: Индекс РТС, индекс ММВБ, акции Сбербанк, акции Газпром, индекс Bovespa, индекс S&P, фьючер на нефть марки BRENT, фьючерс на золото и фьючерс на пару рубль/доллар, посчитаем: приращения логарифма (logdelta = log(Close) — log(Open)). По которым построим линейную регрессию этих приращений и значений индекса оптимизма. То есть формулу вида: индекс оптимизма = A0 + A1*РТС logdelta + A2*ММВБ logdelta + A3*S&P logdelta +…. В результате получим, что два статистически значимых фактора, приращения индекса РТС и индекса ММВБ, и здесь нас ждет первая неожиданность: значимыми оказываются не сами приращения, а их разница (то есть, приращение индекса РТС — приращение индекса ММВБ).
Таким образом выделим новый фактор: РТС logdelta — ММВБ logdelta, и попробуем построить на его основе модель (аналогичную той что была в первой части). Получим:
индекс оптимизма = 15.77*(РТС logdelta — ММВБ logdelta) + 0.095
(черным значения индекса, красным предсказания модели)
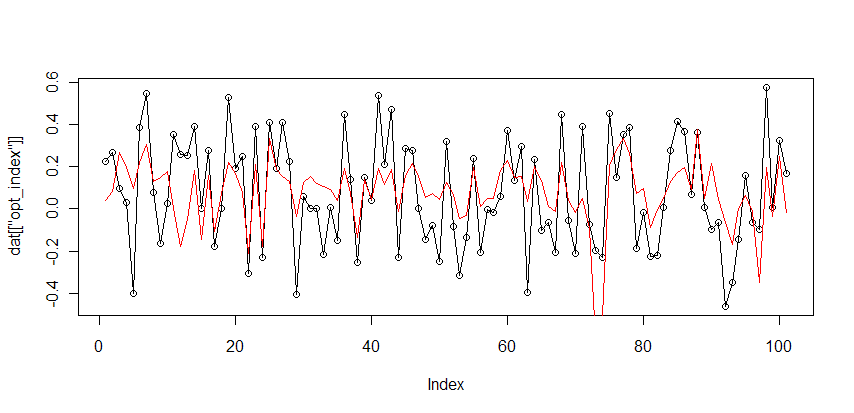
( Читать дальше )
Исследование индекса оптимизма Smart Lab. Часть 1
- 18 сентября 2011, 18:18
- |
Насколько предсказуемо поведение индекса оптимизма? Какие внешние факторы на него влияют, а на сколько это «вещь в себе»? Попытаемся ответить на эти вопросы в ходе исследования.
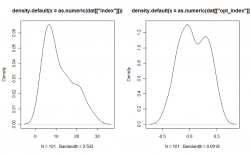
Прежде всего, обратимся к тому как он собственно расчитывается, на данный момент используется довольно простая формула Количество Быков/Количество Медведей. При этом возникают следующие проблемы: распределение индекса совсем не симметрично, резкое изменение соотношения приводит к серьезным «выбросам» (тяжелые хвосты распределения).
<cut>
Поэтому первым делом приведем его к более приемлемому со статистической точки зрения виду. Для этого пересчитаем индекс следующим образом: Процент Быков — Процент Медведей или (X — Y)/(X+Y). Сравним распределение индекса построенного по оригинальной(cлева) и предложенной формуле(справа):
( Читать дальше )
Прежде всего, обратимся к тому как он собственно расчитывается, на данный момент используется довольно простая формула Количество Быков/Количество Медведей. При этом возникают следующие проблемы: распределение индекса совсем не симметрично, резкое изменение соотношения приводит к серьезным «выбросам» (тяжелые хвосты распределения).
<cut>
Поэтому первым делом приведем его к более приемлемому со статистической точки зрения виду. Для этого пересчитаем индекс следующим образом: Процент Быков — Процент Медведей или (X — Y)/(X+Y). Сравним распределение индекса построенного по оригинальной(cлева) и предложенной формуле(справа):
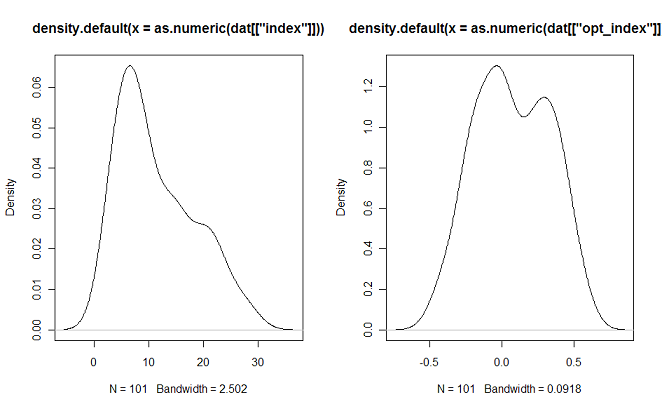
( Читать дальше )
теги блога vlad1024
- algotrading
- AMD
- books
- brexit
- future
- hft
- machine learning
- markets
- mercedes
- perfect world
- python
- research
- smart lab
- statistic
- stocksharp
- акции
- амд
- беспилотники
- бизнес
- биржа
- биткойн
- ВВП
- веселье
- викторина
- вопрос
- геополитика
- Глазьев
- госдума
- данные
- долгосрочные инвестиции
- доллар
- доллар рубль
- закон Яровой
- запад
- ИИ
- инвестиции
- инвестиция
- индекс оптимизма
- интернет
- инфляция
- капитализм
- коинтеграция
- коррекция
- кризис
- Кудрин
- кукловод
- ликбез
- ЛЧИ 2011
- ЛЧИ 2011
- макроэкономика
- маразм крепчал
- модель тренда
- недвижка
- нефть
- новая экономика
- опрос
- оффтоп
- патриотизм
- политика
- популяция
- прохоров
- пузыри
- регулирование
- роскомнадзор
- рубль
- рынок
- системы
- спекулянты
- спекуляции
- статистика
- ТА
- такси
- теория вероятности
- теория Доу
- технический анализ
- торговля
- торговые сигналы
- трамп
- трейдинг
- философия
- форекс
- фундамент
- Хованская
- Хронология
- ЦБ
- электромобиль
- эффективность
- эффективный рынок
- юмор
- я у мамы аналлитик
- яндекс
- яровая