

SMART-LAB
Новый дизайн
Мы делаем деньги на бирже














Информация


Блог им. sherman |Про поиск паттернов
- 27 апреля 2011, 03:16
- |

В последнее время довольно много времени провожу в поисках ценовых паттернов. Интересно, что паттернов, которые явно не случайны довольно много. Неслучайностью предлагаю считать все, что с вероятностью более 50% ведет себя предсказуемо. Например, растет или падает после появления фигуры. Дык вот, оказалось, что главная проблема не в том как найти паттерн, это довольно легко автоматизировать, но проблема в том, что даже если паттерн срабатывает, этого не достаточно для того, чтобы сделать из него что-то путное. Дело в том, что многие паттерны даже при всей своей неслучайности не способны обеспечивать устойчивое отношение средней прибыли к убыткам больше 1. В этом основная проблема. Я объясняю это распределением размера прибыли по «сделкам». Если скажем взять и посчитать какова была максимальная прибыль в растущих днях, то получится вот такая картинка:
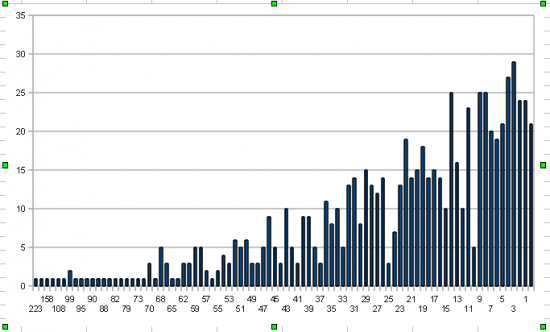
Цифры внизу, это отношения: (close — open) / 100. То есть «купил и держи». Купил на самом открытии и продержал до самого закрытия. А слева, это то, сколько раз это отношение встречалось в истории с середины 2005 года. Поэтому не все паттерны одинаково полезны. Нужно найти не просто неслучайный вход, но еще и такой вход, который может обеспечить прибыль хотя 1.5 к 1. Да, первичную проверку я делаю так. Заходим по сигналу от паттерна. Выходим на следующий день на открытии.
Интересно было бы также узнать какие методики вы применяете при поиске паттернов?
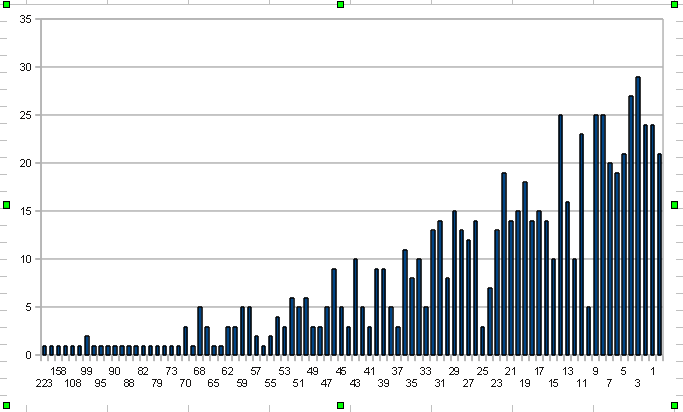
Цифры внизу, это отношения: (close — open) / 100. То есть «купил и держи». Купил на самом открытии и продержал до самого закрытия. А слева, это то, сколько раз это отношение встречалось в истории с середины 2005 года. Поэтому не все паттерны одинаково полезны. Нужно найти не просто неслучайный вход, но еще и такой вход, который может обеспечить прибыль хотя 1.5 к 1. Да, первичную проверку я делаю так. Заходим по сигналу от паттерна. Выходим на следующий день на открытии.
Интересно было бы также узнать какие методики вы применяете при поиске паттернов?
- комментировать
- ★9
- Комментарии ( 16 )
- bitcoin
- brent
- eurusd
- forex
- gbpusd
- gold
- imoex
- nasdaq
- nyse
- rts
- s&p500
- si
- usdrub
- wti
- акции
- алготрейдинг
- анализ
- аналитика
- аэрофлот
- банки
- биржа
- биткоин
- брокеры
- валюта
- вдо
- волновой анализ
- волны эллиотта
- вопрос
- втб
- газ
- газпром
- гмк норникель
- дивиденды
- доллар
- доллар рубль
- евро
- ецб
- золото
- инвестиции
- инфляция
- китай
- коронавирус
- кризис
- криптовалюта
- лидеры роста и падения ммвб
- лукойл
- магнит
- ммвб
- мобильный пост
- мосбиржа
- московская биржа
- нефть
- новатэк
- новости
- обзор рынка
- облигации
- опек+
- опрос
- опционы
- офз
- оффтоп
- прогноз
- прогноз по акциям
- путин
- раскрытие информации
- ри
- роснефть
- россия
- ртс
- рубль
- рынки
- рынок
- санкции
- сбер
- сбербанк
- си
- сигналы
- смартлаб
- сущфакты
- сша
- технический анализ
- торговля
- торговые роботы
- торговые сигналы
- трейдер
- трейдинг
- украина
- финансы
- фондовый рынок
- форекс
- фрс
- фьючерс
- фьючерс mix
- фьючерс ртс
- фьючерсы
- цб
- шорт
- экономика
- юмор
- яндекс