21 сентября 2016, 11:04
Поделитесь, какую структуру базы данных выбирали для более быстрого доступа(сохранения)потоковых данных? какую организацию данных выбрали и почему?
Поделитесь, какую структуру базы данных выбирали для более быстрого доступа(сохранения)потоковых данных? какую организацию данных выбрали и почему?
Читайте на SMART-LAB:

Итоги недели на рынках сырьевых товаров
Если вас интересуют другие аналитические и информационные материалы от банка АО АКБ «ЦентроКредит», смотрите их на нашем сайте в информационном разделе .
Рынок нефти...
16:21

🏦 Новый квартал — новая стратегия
Диверсификация — ключевой принцип для формирования инвестиционного портфеля на фоне смягчения денежно-кредитной политики и геополитической неопределённости. Какие активы в числе фаворитов?...
16:50

7 апреля старт размещения Л-Старт (B.ru, 500 млн руб., YTM 31,89%)
❗️Информация для квалифицированных инвесторов ▶️ На 7 апреля запланировано размещение нового выпуска облигаций Л-Старт ▶️ Основные предварительные параметры выпуска облигаций Л-Старт:...
10:45


VK размещает облигации на 10 млрд рублей VK объявила о планах разместить во второй половине апреля 2026 года биржевые облигации на 10 млрд руб. сроком на 3 года, а сегодня НКР присвоил компании кредит...

Убыток Сургутнефтегаза по РСБУ за 2025 год составил 389,2 млрд руб против прибыли 1,37 млрд руб годом ранее Убыток Сургутнефтегаза по РСБУ за 2025 год составил 389,2 млрд руб против прибыли 1,37 млрд ...

16:52
Тредер,

Дух Анкориджа, здесь уже украинские паблики заверещал, что это их дело рук.

16:51
De Co, будем надеяться…

600 уже близко
Это еще минус 10 %
Потерпите хотя бы до 500 )))
На 300 можно выскакивать навсегда ))

💡Шорт по CNY - лонг по Si: Разбор арбитражной сделки на Мосбирже Ситуация была простая, но показательная.
В вечерку в Si зашел участник и начал давить инструмент вниз через плотности. В итоге появил...

16:50
Иван Иваныч, ты даже от своих слов отказываешься при всех.

НКР присвоил АО «Эталон-Финанс» кредитный рейтинг A-.ru, прогноз стабильный МКПАО «Эталон Груп» (далее – «Компания», «Группа»), одна из крупнейших компаний в сфере девелопмента и строительства на росс...

🏦 Новый квартал — новая стратегия Диверсификация — ключевой принцип для формирования инвестиционного портфеля на фоне смягчения денежно-кредитной политики и геополитической неопределённости.Какие акти...
www.influxdata.com/time-series-platform/influxdb/
Да, в целом направление молодое, может не устроить банк (если я правильно расшифровываю LBBW). У нас работает стабильно, нагрузка на железо при подобном режиме работы — минимальна.
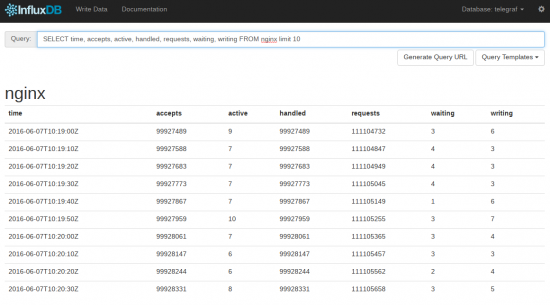
Лучше обычных DB скоростью работы, в десятки раз быстрее.
С данными работать удобно — там поддерживается sql
UPD. Это скриншот из встроенного веб-интерфейса, писать данные можно через HTTP API
docs.influxdata.com/influxdb/v1.0/guides/writing_data/