21 сентября 2016, 11:04
Поделитесь, какую структуру базы данных выбирали для более быстрого доступа(сохранения)потоковых данных? какую организацию данных выбрали и почему?
Поделитесь, какую структуру базы данных выбирали для более быстрого доступа(сохранения)потоковых данных? какую организацию данных выбрали и почему?
Читайте на SMART-LAB:

Сегодня время принимать самое важное решение на следующие полгода!
Пришло время принимать срочное решение!
Брать билет и ехать в Питер к нам на конфу!
Уверяю вас, в ближайшие полгода это самое полезное, что вы можете сделать
👉для своего...

AUD/NZD: Попытка номер два?
Кросс-курс AUD/NZD протестировал линию восходящего тренда, построенную по минимумам 02.07.2025, 20.08.2025 и 02.02.2026 годов, а также оттолкнулся от уровня 1.2035. Последний выступает серединой...
11.06.2026

ЦБ продолжит снижение «ключа», но риторика может ужесточиться
Базовый сценарий аналитиков «Финама» предполагает, что Банк России на ближайшем заседании 19 июня продолжит снижение ключевой ставки, понизив ее еще на 50 б.п., до 14,0%. Но с учетом...
11.06.2026


Gotamcity77, так не надо быть акционером только Газпрома. Также как не надо быть акционером только Сбербанка или только Северстали и т.д. Выбор отдельных акций — это очень рискованный и давно устар...

Вадим, в китае воровство карается смертной казнью)) Не ну серьезно, крупнейшая государственная нефтегазовая корпорация Китая и воровать чужие патенты ради сомнительной выгоды? Да им репутационные р...

Green_Bondholder, а чем вас не устраивает версия покупки инсайдером?

Сокол, так планомерно выпилили «Шляпника» и «бегущего68 года выпуска»… Смысл им нас просвещать, когда сама площадка заточена уже под другое Вернее под других..

Хорошо, что у Сургута 1 НПЗ всего — иу него не такой большой вклад в прибыль, в каком то смысле повезло

К осени просудится какой-нибудь крупный иск и следом подадут на банкротство.

any_to_real, Купившему дно, второе и третье в подарок, и каждый раз «верняк»

Эти петухи обвалили TTF, пока спот не торгуется!!! Жулики Авто-репост. Читать в блоге >>>

ЪЪ, Можин давно был в некоторой степени наставником и старшим товарищем, поддерживая опытом и жизненной мудростью. При занятии подобных должностей физически невозможно существовать без близких един...

А41-70461/2025 — 11.06.2026
Экономические споры по гражданским правоотношениям
Об обращении взыскания на долю в уставном капитале ООО «Тринити»
АЛЕФ-БАНК
АО «КОММЕРЧЕСКАЯ НЕДВИЖИМОСТЬ...
www.influxdata.com/time-series-platform/influxdb/
А насколько они лучше обычных бд. т.е. как там получением данных по каким нить завернутым запросам? :) И в целом удобно ли потом с данными работать?
Да, в целом направление молодое, может не устроить банк (если я правильно расшифровываю LBBW). У нас работает стабильно, нагрузка на железо при подобном режиме работы — минимальна.
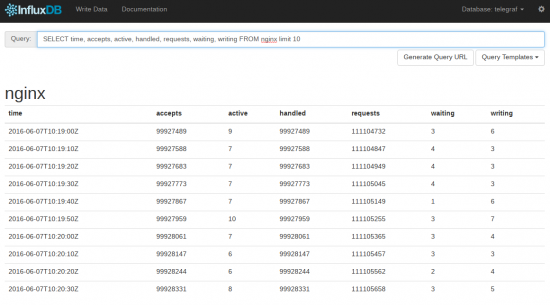
Лучше обычных DB скоростью работы, в десятки раз быстрее.
С данными работать удобно — там поддерживается sql
UPD. Это скриншот из встроенного веб-интерфейса, писать данные можно через HTTP API
docs.influxdata.com/influxdb/v1.0/guides/writing_data/
Поддержка sql это хорошо.
Но думаю, что даже в случае внезапного закрытия проекта (пока считаю маловероятным) у вас есть возможность использовать его ещё лет десять. Бинарники на go отличаются тем, что линкуются полностью статически и не содержат никаких внешних зависимостей. Так что если текущий функционал вас полностью устраивает, то можно годами жить без апдейтов (ну и с учётом того, что это закрытая система, а не наружу в интернет).
На данный момент я использую постргри но в таком очень простом его виде, без всяких там примочек.
Но как то у меня не очень удобные структуры данных выходят, все ж приходит асинхронно, поэтому походу хранить чистые не подготовленные данные самое простое решение, но не самое эфективное.
Кстати, а у этой бд есть какая библиотека под C/C++?
Список актуальных API - https://docs.influxdata.com/influxdb/v1.0/tools/api_client_libraries/
В дальнейшем возможно понадобится эти самые данные обрабатывать онлайн.
Хотя, что вы имеете ввиду онлайн?
Сама система будет работь на лету с данными от брокера в обход бд, но возможно понадобится некоторые вещи подкачивать из базы.
— не грузить БД мелкими sql запросами на добавление
— копить данные в некий промежуточный буфер какое то время и потом разом добавить в БД (лично я после мытрств остановился на том, что делаю это 2 раза в сутки и все).
Исходя из этого, пришлось выбирать БД, которая умеет некий буфер сразу помещать в таблицу, без множественных insert запросов. То есть вам нужно добавить к примеру в таблицу 1000 записей и она будет делать не 1000 инсертов, а один какой то свой метод. FIREBIRD например так делать не умеет.
Так умеет делать например:
— sybase
— так умеет делать c# с Entity Framework в связке с Microsoft SQL (тут вообще можно на потоки разделить, если ядер не одно)
— еще какие нибудь БД, с которыми я не столкнулся =)
На примере, если нужно добавить тысяч 200 записей, 200т инсертов может занять минут 8, особенно если много индексов.
Подход через промежуточный буфер решает это секунд за 7-10.
Но тогда второй вопрос, быстро обрабатывать потом данные. Тут уже придется грамотно выстроить индексацию полей и sql запросы на выборку. Вооружайтесь тогда анализаторами и боритесь за секунды =)) При этом надо иметь ввиду, что большое кол-во индексов прямиком влияет на время добавления данных. Приходится все время варьировать в этом вопросе, что выбрать, быстрый insert или быстрый select
В моем случае работа с бд, и работа системы онлайн как бы разделены. Но никто ж не знает как оно будет в будущем )).
А используете чистые данные для записи или делаете какую то предобработку, форматирование?
Но если вы познакомитесь с современными плюшками, там уже даже думать не надо. =)) это я про Entity Framework. Олд скул программирование БД все больше уходит в прошлое =))
Насколько понимаю, твоя задача тривиальна и решается по сути двумя способами(без костылей), Это мелгомягкие технологии или Джава Энтерпрайз(EJB 3.0)- зачем изобретать велоcипеды?
Если брать обычную бд, и сырые данные, то получается что мы имеем много так сказать не нужной информации… тот же тикер ид в каждой из таблиц, но как то же надо их связывать и идентифицировать.
Хотел узнать может есть какой опыт наработанный уже. Что бы не натыкаться на ошибки проектирования :). Но как Андрей сказал имееет смысл смотреть на конкретных задачах.
по поводу .net и явы… первое хорошо но у меня связка c++/qt… ну и иногда питон. А яву я по религиозным причинам не люблю %)