Искусственный трейдер. Часть 1. Подготовка данных для машинного обучения (видео).
Всех с наступающим (и никаких отступлений!) Днем Защитника Отечества ака Денем Советской Армии и Военно-Морского Флота!
И за тех, кто в море! Ну а те кто в ЗОЖе, начинаем готовить себе замену — искусственного трейдера.
Важнейшей частью любого алгоритма машинного обучения являются данные, на которых происходит обучение, а еще важнее качество этих данных.
Для приготовления искусственного трейдера нам понадобятся следующие ингредиенты:
1.Установленная платформа Jatotrader (FREE или круче) версии 2.9.3 или выше. Можно обойтись и без установки Джато и взять тестовый набор данных отсюда. Описание содержимого файлов датасета — в конце топика.
2.Питон.Jupyter Notebook (Anaconda3)
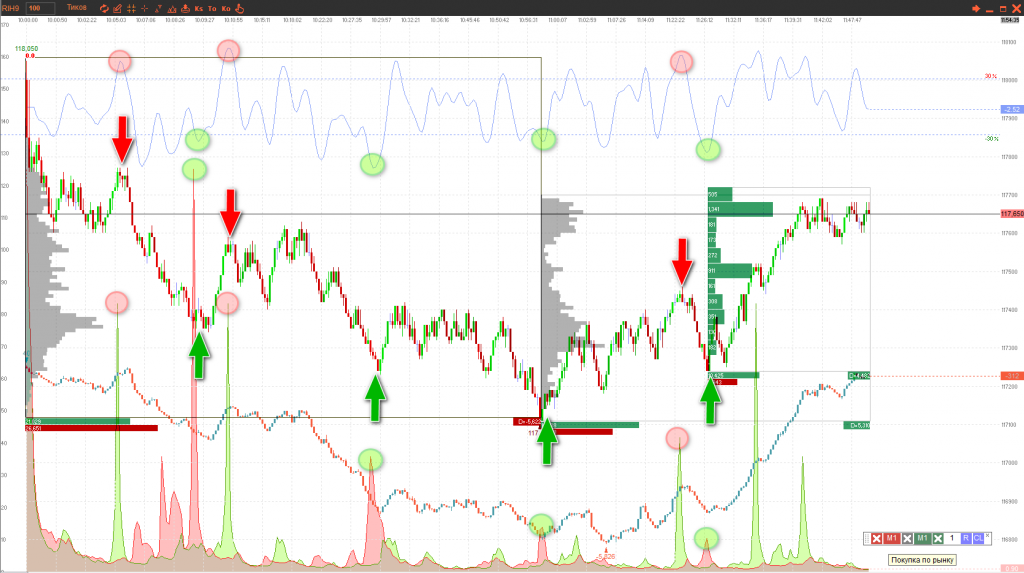
Короче говоря, Jatotrader мы используем как предварительный обработчик и генератор данных для машинного обучения (МО), а Python для создания модели, обученной на этих данных. Возможности Jatotrader позволяют создавать частотные графики из тиковых данных, примерно такого вида
На них четко видна зависимость изменения цены от действий участников. Вот эти данные и будут использоваться для МО.
В этом коротком видео (2:24) показано как создать собственные датасеты (на примере фьючерса BRH0) с различными частотными характеристиками.
Каждый открытый частотный график после воспроизведения истории создает csv файл в папке \Jatotrader\DATASET\Тикер с именем ГГГГ-ММ-ДД_Тикер_Метод_Количество.FRQ Метод и количество — это способы формирования частотного бара: например 500 тиков на бар, 50 пунктов цены на бар(Ренко), 1000 маркет-дельты на бар (изменение значения маркет-дельты по модулю от предыдущего значения), 30 секунд на бар и т.д.
Сам процесс создания датасетов весьма ресурсозатратен.Так, создание датасета за 16 торговых сессий для 20 частотных настроек (графиков) для BRH0 у меня занимает около 5 минут.
После того, как набор данных создан, его нужно прочитать в Питоне, «распарсить» и отобразить:
.")
В следующем топике рассмотрим исходный код "парсера" и «визуализатора» данных из Jatotrader в Python. Для этого установите Jupyter Notebook (Anaconda3)
Описание файлов датасета.
Пример: в файле 2020-02-03_RIH0_TICKS_500.FRQ содержится информация за 3 февраля 2020 года по фьючерсному контракту RIH0,
сформированная из расчета 500 тиков на бар. Первая строка файла — это имена столбцов DATETIME,H,L,O,C,DH,DL,DO,DC,OTO,BI,SI,BV,SV,BC,SC. Последующие строки — это бары, идущие в хронологическом порядке. DATETIME-строка в формате «ГГГГ-ММ-ДД ЧЧ: ММ: СС», H,L,O,C — максимальная, минимальная цена и цена открытия и закрытия бара. DH и DL — максимальное и минимальное значение накопленной маркет-дельты бара, DO и DC — значение маркет-дельты при открытии и закрытии бара. OTO — значение объемно-тикового осциллятора на закрытии бара, BI-интенсивность покупок (тиков в секунду), SI- интенсивность продаж, BV-объем покупок, SV-объем продаж, BC-количество покупок,SC-количество продаж
Скачать Jatotrader можно здесь. Как получить ключ в этом видео. Как подключиться к КВИКУ смотри здесь. С 8-м Квиком пока не работает, доделываю. Подписаться на мой канал можно здесь в ютьюбе.
 Евгений Шибаев22 февраля 2020, 13:40Это графики, на которых отображены помимо цены и объема частотные характеристики, такие как интенсивности покупок и продаж, объемно-тиковый осциллятор, скорость ленты и т.д. Выглядят примерно так:
Евгений Шибаев22 февраля 2020, 13:40Это графики, на которых отображены помимо цены и объема частотные характеристики, такие как интенсивности покупок и продаж, объемно-тиковый осциллятор, скорость ленты и т.д. Выглядят примерно так: 0
0 For_post22 февраля 2020, 13:58был чувак у меня со знакомой фамилией. это ты? — упырь?)0
For_post22 февраля 2020, 13:58был чувак у меня со знакомой фамилией. это ты? — упырь?)0 Александр Дрыгун22 февраля 2020, 14:14Что-то на Data Science похожа0
Александр Дрыгун22 февраля 2020, 14:14Что-то на Data Science похожа0- Александр Дрыгун22 февраля 2020, 14:30А в реальной торговле не пробовали этот бот0