

SMART-LAB
Новый дизайн
Мы делаем деньги на бирже














Информация


Блог им. gift
Методы Машинного обучения (Data Mining)
- 04 февраля 2012, 12:58
- |

Доказав себе однажды, что ни один из индикаторов по отдельности или в совокупности с другими работают неудовлетворительно (по тестам от 3-х лет и более) я пришел к простейшим методам Data Mining, которые показали очень хорошие результаты. Пришла пора капнуть глубже, тут как раз и аккуратненькая подборочка, для поверхностного ознакомления, нашлась.
А вы используете в своей торговле подобные штуки?
Метод опорных векторов
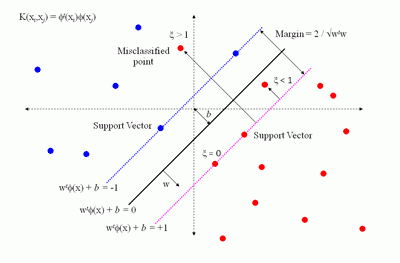
Метод опорных векторов был разработан Владимиром Вапником в 1995 году [86] и впервые применен к задаче классификации текстов Йоахимсом (Joachims) в 1998 году в работе. В своем первоначальном виде алгоритм решал задачу различения объектов двух классов. Метод приобрел огромную популярность благодаря своей высокой эффективности. Многие исследователи использовали его в своих работах, посвященных классификации текстов. Подход, предложенный Вапником для определения того, к какому из двух заранее определенных классов должен принадлежать анализируемый образец, основан на принципе структурной минимизации риска. Вероятность ошибки при классификации оценивается, как непрерывная убывающая функция, от расстояния между вектором и разделяющей плоскостью. Она равна 0,5 в нуле и стремится к 0 на бесконечности.
Результаты классификации текстов с помощью метода опорных векторов, являются одними из лучших, по сравнению с остальными методами машинного обучения. Однако, скорость обучения данного алгоритма одна из самых низких. Метод опорных векторов требует большого объема памяти и значительных затрат машинного времени на обучение.
Метод k–ближайших соседей
Метод k-ближайших соседей является одним из самых изученных и высокоэффективных алгоритмов, используемых при создании автоматических классификаторов. Впервые он был предложен еще в 1952 году для решения задач дискриминантного анализа.
В основе метода лежит очень простая идея: находить в отрубрицированной коллекции самые похожие на анализируемый текст документы и на основе знаний об их категориальной принадлежности классифицировать неизвестный документ.
Рассмотрим алгоритм подробнее. При классификации неизвестного документа находится заранее заданное число k текстов из обучающей выборки, которые в пространстве признаков расположены к ближе всего. Иными словами находятся k-ближайших соседей. Принадлежность текстов к распознаваемым классам считается известной. Параметр k обычно выбирают от 1 до 100. Близость классифицируемого документа и документа, принадлежащего категории, определяется как косинус угла между их векторами признаков. Чем значение ближе к 1, тем документы больше друг на друга похожи.
Решение об отнесении документа к тому или иному классу принимается на основе анализа информации о принадлежности k его ближайших соседей. Например, коэффициент соответствия рубрики анализируемому документу, можно выяснить путем сложения для этой рубрики значений.
При монотематической классификации выбирается рубрика с максимальным значении. Если же документ может быть приписан к нескольким рубрикам (случай мультитематической классификации), классы считаются соответствующими, если значение превосходит некоторый, заранее заданный порог.
Главной особенностью, выделяющей метод k-NN среди остальных, является отсутствие у этого алгоритма стадии обучения. Иными словами, принадлежность документа рубрикам определяется без построения классифицирующей функции.
Основным преимуществом такого подхода является возможность обновлять обучающую выборку без переобучения классификатора. Это свойство может быть полезно, например, в случаях, когда обучающая коллекция часто пополняется новыми документами, а переобучение занимает слишком много времени.
Классический алгоритм предлагает сравнивать анализируемый документ со всеми документами из обучающей выборки и поэтому главный недостаток метода k-ближайших соседей заключается в длительности времени работы рубрикатора на этапе классификации.
Деревья решений
В отличии от остальных подходов представленных здесь, подход, получивший название деревья решений относится к символьным (т.е. не числовым) алгоритмам. Преимущество символьных алгоритмов, заключается в относительной простоте интерпретации человеком правил отнесения документов к рубрике. Они хорошо приспособлены для графического отображения, и поэтому сделанные на их основе выводы гораздо легче интерпретировать, чем, если бы они были представлены только в числовой форме.
Цель построения деревьев решений заключается в п
редсказании значений категориальной зависимой переменной, и поэтому используемые методы тесно связаны с более традиционными методами дискриминантного и кластерного анализа, а также нелинейного оценивания и непараметрической статистики. Обширная сфера применения деревьев решений делает их весьма удобным инструментом для анализа данных и позволяет решать как задачи классификации и регрессии, так и задачи описания данных.
Деревья решений — метод, применяемый при многоходовом процессе анализа данных и принятии решений о категориальной принадлежности. Ветви дерева изображают события, которые могут иметь место, а узлы и вершины — момент выбора направления действий. Принятие решений осуществляется на основе логической конструкции «если… то…», путем ответа на вопрос вида «является ли значение переменной меньше значения порога?». При положительном ответе осуществляется переход к правому узлу дерева, при отрицательном к левому узлу. После этого осуществляется принятие решения уже для выбранного узла.
Для более ясного понимания принципов работы деревьев решений представим следующую ситуацию. Перед нами стоит задача сортировки камней на крупные, средние и мелкие. Эти классы камней отличаются линейными размерами, и вследствие этого данный параметр может быть использован для построения иерархического устройства сортировки камней. Предположим, у нас имеется два сита, размер ячеек которых соответствует минимальному размеру крупных камней, и минимальному размеру средних камней, соответственно. Далее все камни высыпаются в первое сито. Те из них, что не прошли просеивание считаются крупными камнями, а те, что прошли – средними и мелкими. Затем камни высыпаются во второе сито. Те камни, что остались во втором сите считаются принадлежащими среднему классу камней, а те, что прошли сквозь него – мелкому.
Рассмотрим применения деревьев решений к автоматической классификации текста. В этом случае внутренние узлы представляют собой термы, ветви, отходящие от них, характеризуют вес терма в анализируемом документе, а листья — категории. Такой классификатор категоризирует испытываемый документ, рекурсивно проверяя веса вектора признаков по отношению к порогам, выставленным для каждого из весов, пока не достигнет листа дерева (категории). К этой категории (листа которой достиг классификатор) и приписывается анализируемый документ.
Метод Байеса
Метод Байеса это простой классификатор, основанный на вероятностной модели, имеющей сильное предположение независимости компонент вектора признаков [95, 96]. Обычно это допущение не соответствует действительности и потому одно из названий метода — Naıve Bayes (Наивный Байес).
Вероятностная модель метода основана на известной формуле Байеса по вычислению апостериорной вероятности гипотез. Применяя эту формулу для задачи классификации текстов, получим вероятность того, что документ принадлежит категории :
Так как знаменатель не зависит от рубрики и является константой, на практики его сокращают. Основываясь на этом, получим формулу для определения принадлежности документа к рубрикам :
Условная вероятность вычисляется как:
Для облегчения задачи вычисления этой вероятности предположим независимость компонент вектора признаков. Тогда:
Как и все вероятностные классификаторы, классификатор, основанный на методе Байеса, правильно классифицирует документы, если соответствующий документу класс более вероятен, чем любой другой. В этом случае формула для определения наиболее вероятной категории примет следующий вид:
Предположим, что классификатор состоит из рубрик и может быть выражена через параметров. Тогда соответствующий алгоритм Байеса для классификации текста будет иметь параметров. Но на практике, чаше всего (случай бинарной классификации) и . Поэтому, число параметров для метода Байеса обычно равно , где — размерность вектора признаков.
Наивный классификатор Байеса имеет несколько свойств, которые делают его чрезвычайно полезным практически, несмотря на то, что сильные предположения независимости часто нарушаются. Этот метод показывает высокую скорость работы и достаточно высокое качество классификации [91, 96]. Его можно рекомендовать для построения классификатора, когда существую жесткие ограничения на время счета и воспользоваться более точными методами, не представляется возможны.
Метод Роше
Одним из наиболее простых классификаторов, основанных на векторной модели, является так называемый классификатор Роше. Основная особенность этого метода заключается в том, что для каждой рубрики вычисляется взвешенный центроид. Он получается вычитанием веса каждого терма векторов признаков не соответствующих рубрике документов, из весов термов векторов признаков соответствующих рубрике документов.
Пусть каждый документ рубрики будет представлен в виде вектора признаков следующим образом. Тогда рубрика будет представлена в виде вектора признаков. Для каждой рубрики вычисляется взвешенный центроид.
Таким образом, получившийся взвешенный центроид представляет рубрику в пространстве признаков. Принадлежность рубрикам неизвестного документа, определяется путем вычисления расстояния между центроидом каждой из рубрик и вектором классифицируемого документа. Если расстояние не превосходит некоторый, заранее заданный порог, документ считается принадлежащим данной рубрике.
Практическое исследования метода Роше показали, что данный метод обладает высокой эффективностью в решении задачи классификации текстов. Одной из главных его особенностей является возможность изменять вектор взвешенного центроида рубрики, без переобучения классификатора. Это свойство может быть полезно, например, в случаях, когда обучающая коллекция часто пополняется новыми документами, а переобучение занимает слишком много времени. Благодаря своей результативности и простоте метод Роше стал одним из самых популярных в рассматриваемой нами области и часто используется как базовый, для сравнения эффективности различных классификаторов.
Метод «случайный лес»

Алгоритм «случайный лес» — техника, с помощью которой можно достичь высокой точности в классификации и регрессии с минимальной настройкой параметров.
В этом методе модель классификатора строится с помощью обучающей выборки, на основе которой строится большое число независимых деревьев решений. Деревья создаются так, чтобы для каждого дерева, вместо того, чтобы рассматривать все возможные узлы, анализ проводился для маленькой группой случайно отобранных узлов. В этом случае для каждого дерева, в целях последующего анализа, выбирается лучший лист. Классификации происходит голосованием либо усреднением результатов для всех деревьев.
Случайность в этом методе присутствует в выборе примеров из обучающей выборки для построения деревьев решений, а также в выборе узлов, для которых будет работать алгоритм каждого конкретного дерева решений.
Точность классификации в методе «случайный лес» зависит от численности построенных деревьев решений, а также от их взаимной корреляции. То есть в идеальном случае для каждой рубрики мы должны построить большое количество независимых деревьев решений. Если эффективность каждого конкретного дерева решений падает или возрастает их зависимость, в этом случае снижается и точность классификации этого метода. В случае алгоритма «случайный лес», независимость деревьев решений достигается через случайность в выборе примеров из обучающей выборки и через случайность в выборе для каждого дерева узлов, по которым проводится анализ.
Метод «случайный лес» обладает множеством положительных особенностей: параллельность работы, высокая точность, быстрая обучаемость, и тенденция к отсутствию переобучаемости.
Также, его положительной особенностью является то, что он показывает высокое качество рубрикации для обучающих выборок, с малым количеством примеров. Это свойство выделяет метод «случайный лес» среди множества других алгоритмов и является чрезвычайно ценным для успешного применения методов машинного обучения.
А вы используете в своей торговле подобные штуки?
Метод опорных векторов
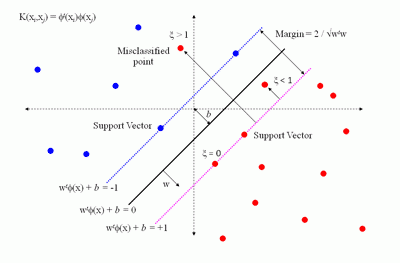
Метод опорных векторов был разработан Владимиром Вапником в 1995 году [86] и впервые применен к задаче классификации текстов Йоахимсом (Joachims) в 1998 году в работе. В своем первоначальном виде алгоритм решал задачу различения объектов двух классов. Метод приобрел огромную популярность благодаря своей высокой эффективности. Многие исследователи использовали его в своих работах, посвященных классификации текстов. Подход, предложенный Вапником для определения того, к какому из двух заранее определенных классов должен принадлежать анализируемый образец, основан на принципе структурной минимизации риска. Вероятность ошибки при классификации оценивается, как непрерывная убывающая функция, от расстояния между вектором и разделяющей плоскостью. Она равна 0,5 в нуле и стремится к 0 на бесконечности.
Результаты классификации текстов с помощью метода опорных векторов, являются одними из лучших, по сравнению с остальными методами машинного обучения. Однако, скорость обучения данного алгоритма одна из самых низких. Метод опорных векторов требует большого объема памяти и значительных затрат машинного времени на обучение.
Метод k–ближайших соседей
Метод k-ближайших соседей является одним из самых изученных и высокоэффективных алгоритмов, используемых при создании автоматических классификаторов. Впервые он был предложен еще в 1952 году для решения задач дискриминантного анализа.
В основе метода лежит очень простая идея: находить в отрубрицированной коллекции самые похожие на анализируемый текст документы и на основе знаний об их категориальной принадлежности классифицировать неизвестный документ.
Рассмотрим алгоритм подробнее. При классификации неизвестного документа находится заранее заданное число k текстов из обучающей выборки, которые в пространстве признаков расположены к ближе всего. Иными словами находятся k-ближайших соседей. Принадлежность текстов к распознаваемым классам считается известной. Параметр k обычно выбирают от 1 до 100. Близость классифицируемого документа и документа, принадлежащего категории, определяется как косинус угла между их векторами признаков. Чем значение ближе к 1, тем документы больше друг на друга похожи.
Решение об отнесении документа к тому или иному классу принимается на основе анализа информации о принадлежности k его ближайших соседей. Например, коэффициент соответствия рубрики анализируемому документу, можно выяснить путем сложения для этой рубрики значений.
При монотематической классификации выбирается рубрика с максимальным значении. Если же документ может быть приписан к нескольким рубрикам (случай мультитематической классификации), классы считаются соответствующими, если значение превосходит некоторый, заранее заданный порог.
Главной особенностью, выделяющей метод k-NN среди остальных, является отсутствие у этого алгоритма стадии обучения. Иными словами, принадлежность документа рубрикам определяется без построения классифицирующей функции.
Основным преимуществом такого подхода является возможность обновлять обучающую выборку без переобучения классификатора. Это свойство может быть полезно, например, в случаях, когда обучающая коллекция часто пополняется новыми документами, а переобучение занимает слишком много времени.
Классический алгоритм предлагает сравнивать анализируемый документ со всеми документами из обучающей выборки и поэтому главный недостаток метода k-ближайших соседей заключается в длительности времени работы рубрикатора на этапе классификации.
Деревья решений
В отличии от остальных подходов представленных здесь, подход, получивший название деревья решений относится к символьным (т.е. не числовым) алгоритмам. Преимущество символьных алгоритмов, заключается в относительной простоте интерпретации человеком правил отнесения документов к рубрике. Они хорошо приспособлены для графического отображения, и поэтому сделанные на их основе выводы гораздо легче интерпретировать, чем, если бы они были представлены только в числовой форме.
Цель построения деревьев решений заключается в п
редсказании значений категориальной зависимой переменной, и поэтому используемые методы тесно связаны с более традиционными методами дискриминантного и кластерного анализа, а также нелинейного оценивания и непараметрической статистики. Обширная сфера применения деревьев решений делает их весьма удобным инструментом для анализа данных и позволяет решать как задачи классификации и регрессии, так и задачи описания данных.
Деревья решений — метод, применяемый при многоходовом процессе анализа данных и принятии решений о категориальной принадлежности. Ветви дерева изображают события, которые могут иметь место, а узлы и вершины — момент выбора направления действий. Принятие решений осуществляется на основе логической конструкции «если… то…», путем ответа на вопрос вида «является ли значение переменной меньше значения порога?». При положительном ответе осуществляется переход к правому узлу дерева, при отрицательном к левому узлу. После этого осуществляется принятие решения уже для выбранного узла.
Для более ясного понимания принципов работы деревьев решений представим следующую ситуацию. Перед нами стоит задача сортировки камней на крупные, средние и мелкие. Эти классы камней отличаются линейными размерами, и вследствие этого данный параметр может быть использован для построения иерархического устройства сортировки камней. Предположим, у нас имеется два сита, размер ячеек которых соответствует минимальному размеру крупных камней, и минимальному размеру средних камней, соответственно. Далее все камни высыпаются в первое сито. Те из них, что не прошли просеивание считаются крупными камнями, а те, что прошли – средними и мелкими. Затем камни высыпаются во второе сито. Те камни, что остались во втором сите считаются принадлежащими среднему классу камней, а те, что прошли сквозь него – мелкому.
Рассмотрим применения деревьев решений к автоматической классификации текста. В этом случае внутренние узлы представляют собой термы, ветви, отходящие от них, характеризуют вес терма в анализируемом документе, а листья — категории. Такой классификатор категоризирует испытываемый документ, рекурсивно проверяя веса вектора признаков по отношению к порогам, выставленным для каждого из весов, пока не достигнет листа дерева (категории). К этой категории (листа которой достиг классификатор) и приписывается анализируемый документ.
Метод Байеса

Метод Байеса это простой классификатор, основанный на вероятностной модели, имеющей сильное предположение независимости компонент вектора признаков [95, 96]. Обычно это допущение не соответствует действительности и потому одно из названий метода — Naıve Bayes (Наивный Байес).
Вероятностная модель метода основана на известной формуле Байеса по вычислению апостериорной вероятности гипотез. Применяя эту формулу для задачи классификации текстов, получим вероятность того, что документ принадлежит категории :
Так как знаменатель не зависит от рубрики и является константой, на практики его сокращают. Основываясь на этом, получим формулу для определения принадлежности документа к рубрикам :
Условная вероятность вычисляется как:
Для облегчения задачи вычисления этой вероятности предположим независимость компонент вектора признаков. Тогда:
Как и все вероятностные классификаторы, классификатор, основанный на методе Байеса, правильно классифицирует документы, если соответствующий документу класс более вероятен, чем любой другой. В этом случае формула для определения наиболее вероятной категории примет следующий вид:
Предположим, что классификатор состоит из рубрик и может быть выражена через параметров. Тогда соответствующий алгоритм Байеса для классификации текста будет иметь параметров. Но на практике, чаше всего (случай бинарной классификации) и . Поэтому, число параметров для метода Байеса обычно равно , где — размерность вектора признаков.
Наивный классификатор Байеса имеет несколько свойств, которые делают его чрезвычайно полезным практически, несмотря на то, что сильные предположения независимости часто нарушаются. Этот метод показывает высокую скорость работы и достаточно высокое качество классификации [91, 96]. Его можно рекомендовать для построения классификатора, когда существую жесткие ограничения на время счета и воспользоваться более точными методами, не представляется возможны.
Метод Роше
Одним из наиболее простых классификаторов, основанных на векторной модели, является так называемый классификатор Роше. Основная особенность этого метода заключается в том, что для каждой рубрики вычисляется взвешенный центроид. Он получается вычитанием веса каждого терма векторов признаков не соответствующих рубрике документов, из весов термов векторов признаков соответствующих рубрике документов.
Пусть каждый документ рубрики будет представлен в виде вектора признаков следующим образом. Тогда рубрика будет представлена в виде вектора признаков. Для каждой рубрики вычисляется взвешенный центроид.
Таким образом, получившийся взвешенный центроид представляет рубрику в пространстве признаков. Принадлежность рубрикам неизвестного документа, определяется путем вычисления расстояния между центроидом каждой из рубрик и вектором классифицируемого документа. Если расстояние не превосходит некоторый, заранее заданный порог, документ считается принадлежащим данной рубрике.
Практическое исследования метода Роше показали, что данный метод обладает высокой эффективностью в решении задачи классификации текстов. Одной из главных его особенностей является возможность изменять вектор взвешенного центроида рубрики, без переобучения классификатора. Это свойство может быть полезно, например, в случаях, когда обучающая коллекция часто пополняется новыми документами, а переобучение занимает слишком много времени. Благодаря своей результативности и простоте метод Роше стал одним из самых популярных в рассматриваемой нами области и часто используется как базовый, для сравнения эффективности различных классификаторов.
Метод «случайный лес»
Алгоритм «случайный лес» — техника, с помощью которой можно достичь высокой точности в классификации и регрессии с минимальной настройкой параметров.
В этом методе модель классификатора строится с помощью обучающей выборки, на основе которой строится большое число независимых деревьев решений. Деревья создаются так, чтобы для каждого дерева, вместо того, чтобы рассматривать все возможные узлы, анализ проводился для маленькой группой случайно отобранных узлов. В этом случае для каждого дерева, в целях последующего анализа, выбирается лучший лист. Классификации происходит голосованием либо усреднением результатов для всех деревьев.
Случайность в этом методе присутствует в выборе примеров из обучающей выборки для построения деревьев решений, а также в выборе узлов, для которых будет работать алгоритм каждого конкретного дерева решений.
Точность классификации в методе «случайный лес» зависит от численности построенных деревьев решений, а также от их взаимной корреляции. То есть в идеальном случае для каждой рубрики мы должны построить большое количество независимых деревьев решений. Если эффективность каждого конкретного дерева решений падает или возрастает их зависимость, в этом случае снижается и точность классификации этого метода. В случае алгоритма «случайный лес», независимость деревьев решений достигается через случайность в выборе примеров из обучающей выборки и через случайность в выборе для каждого дерева узлов, по которым проводится анализ.
Метод «случайный лес» обладает множеством положительных особенностей: параллельность работы, высокая точность, быстрая обучаемость, и тенденция к отсутствию переобучаемости.
Также, его положительной особенностью является то, что он показывает высокое качество рубрикации для обучающих выборок, с малым количеством примеров. Это свойство выделяет метод «случайный лес» среди множества других алгоритмов и является чрезвычайно ценным для успешного применения методов машинного обучения.
теги блога Александр Дрозд
- bitcoin
- wealth lab
- акции
- алгоритм
- алгоритмическая торговля
- алгоритмы
- алготрейдинг
- американские акции
- Американский рынок
- аналитика
- аналитики
- биржа
- биткоин
- внутридневная система
- волатильность
- вопросы и ответы
- Горчаков
- грааль
- Греция
- деньги
- дефолт
- диверсификация
- доходность
- доходы
- ДУ
- еврозона
- европа
- жадность
- золотые слова
- идеи
- инвестиции
- итоги месяца
- итоги сентября
- китай
- комиссия
- кризис
- криптовалюты
- кукловоды
- лайткоины
- ЛЧИ
- математика
- математическое ожидание
- мегафон
- Миловидов
- мобильный пост
- модель
- мультфильм
- нефть
- облигации
- октябрь
- опрос
- опыт
- оффтоп
- плечи
- плюсики
- польза обществу
- потери
- прогнозы
- программирование
- просадки
- проскальзывание
- психология
- рейтинг
- РИ
- риск
- риски
- робот
- роботы
- ртс
- рынки
- рынок
- система
- системная торговля
- системный трейдинг
- системы
- смартлаб
- статистика
- Стратегии
- стратегия
- страх
- сша
- технический анализ
- топики
- торговая система
- торговые системы
- трейдеры
- трейдинг
- управляющие
- физика
- финансы
- фондовый рынок
- фьючерс
- фьючерсы
- Хазин
- хэдж фонд
- Ценная подборка
- шум
- эквити
- экономика
- 2012
Использовать можно что угодно ) чтобы работал data-mining (black-box модели), нужно множество статистически значимо скореллированных с результатом факторов. А сам по себе data-mining это просто апроксимация плотности вероятности в некотором высоко размерном пространстве этих факторов.
пашел учить матчасть…
если нет алгоритма то идея просто говно!!!
Дайте подробно код или хотя бы его основные вещи!!!
И покажите свою доходность у брокера, тогда посмотрим как это все в реале работает.
а пока это все красивые слова и грамотно изложенная идея. и не чего больше, вообщем очередное гавно!!!
Но этого не достаточно, нужно определиться с Вашим отношением к риску и количеством капитала, который Вы готовы на все это дело поставить.Но пред этим всем с начало нужно еще систему прогнать на других инструментах(желательно не скоррелированых, между собой ) без оптимизации и посмотреть какие там будут результаты!!! потому что Вы оптимизируете под определенный рынок, который уже не когда не повторится, а повторится уже в неком измененном состоянии, что так же делает некий минус данному алгоритму.Так же прежде чем поставить алгоритм на роботу с реальными деньгами, желательно что бы он на небольшой сумме денег поторговал в реале, да бы посмотреть правильно ли он работает в реальных условиях(не менее 10-20 сделок, чем больше тем лучше)И только после этого ставить его на реальные деньги и быть готовым к тому, что сразу начнется торговля с убыточного момента(с допустимой просадки, которая может увеличится в реале)И даже после всего это у Вас нет не каких гарантий что алгоритм будет зарабатывать))Ведь трейдинг, как показывает практика это постоянный поиск идей и их воплощение и главное в нем вовремя остановиться))